Тема
Оценка качества, наблюдаемость и надежность
Измерять поведение ИИ, ловить регрессии, отслеживать стоимость и задержки, улучшать процессы.
12 материалов (5 статей · 7 видео)
Начните здесь
Несколько хороших первых материалов перед полной лентой.
 10 мин чтения
10 мин чтенияСтатья
Оценки для не-инженеров: как понять, ваш ИИ-процесс становится лучше или хуже
Оценки — систематическое измерение качества выводов ИИ — обычно считают инженерной темой. Но они нужны любой команде, у которой есть ИИ-процессы, и базовый уровень доступен без кода. Как это делать.
Измерять, улучшается ли ИИ-процесс, с помощью примеров, рубрик и регрессионных проверок.
Уверенный
 13 мин чтения
13 мин чтенияСтатья
Строим evals, которые реально ловят регрессии
Большинство eval-наборов выглядят внушительно, но пропускают реальные регрессии. Чтобы построить evals, которые ловят важное, нужны аккуратно собранный датасет, чувствительные метрики, калиброванные судьи и культура доверия. Паттерны команд, у которых это получается.
Оценить архитектурный подход, возможные сбои и защитные меры до разработки.
Эксперт
 12 мин чтения
12 мин чтенияСтатья
Наблюдаемость LLM-приложений: трассировка, стоимость, задержка, дрейф качества
LLM-приложения ломаются по-особенному, и традиционная наблюдаемость это упускает. Шаблоны для трассировки многошаговых потоков, отслеживания стоимости, которая меняется в 100 раз между вызовами, мониторинга дрейфа качества и отладки галлюцинаций в продакшене.
Оценить архитектурный подход, возможные сбои и защитные меры до разработки.
Эксперт
Еще по этой теме
 48 мин
48 минВидео
Как строить надёжных AI-агентов: контекст и evals
Arize AI. Объясняет, почему агенты в продакшене ломаются без правильного контекста, данных для оценки, трассировки и доменной экспертизы. Это хорошо ложится на реестр отказов из статьи: отделяйте поиск от рассуждения, определяйте ожидаемые результаты, оценивайте вызовы инструментов и трассируйте ошибки до смены модели.
Эксперт
 10 мин чтения
10 мин чтенияСтатья
Сбои production AI: что ломается после демо
AI-системы обычно ломаются предсказуемо: hallucination, stale context, sycophancy, prompt injection, unsafe tool use, schema drift и weak fallbacks. Реестр production failure modes для команд, которые запускают реальные workflows.
Построить production AI failure-mode register с контролями для hallucination, stale context, prompt injection, unsafe tool use и weak fallbacks.
Эксперт
 11 мин чтения
11 мин чтенияСтатья
Чанкинг, переранжирование и гибридный поиск: как заставить RAG реально работать
Большинство RAG-реализаций работают плохо, потому что неправильно делают три вещи. Практический гид по чанкингу документов, переранжированию результатов и сочетанию ключевого поиска с семантическим — без необходимости становиться поисковым инженером.
Оценить архитектурный подход, возможные сбои и защитные меры до разработки.
Уверенный
 154 мин
154 минВидео
Instrumenting & Evaluating LLMs
Hamel Husain. Хамел Хусейн, Юджин Ян, Брайан Бишоф, Харрисон Чейз и Шрея Шанкар прорабатывают трассировку, анализ логов, LLM-as-judge и воркфлоу вокруг просмотра реальных продакшен-данных. Сядьте с этим как с длинным подкастом — это лучший глубокий разбор тезиса статьи «смотрите на свои трассировки» на YouTube.
Эксперт
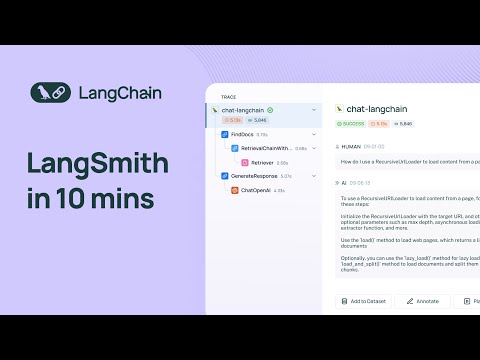 9 мин
9 минВидео
LangSmith in 10 Minutes
LangChain. Гид по LLM-трассе, проекту и датасету от ко-фаундера LangChain — стоимость по токенам, латентность, error rate, агрегация обратной связи, погружение в один спан шага retrieval. Это ближайший визуальный аналог тому, что описывает статья, говоря «каждый вызов — это спан» и почему структурированные трассировки бьют print-логирование.
Эксперт
 109 мин
109 минВидео
Stanford CME295 Transformers & LLMs | Autumn 2025 | Lecture 8 - LLM Evaluation
Stanford Online. Методичный проход по rule-based метрикам, смещениям LLM-as-judge, оценке фактологичности и агентов и режимам отказа статичных бенчмарков. Используйте как теоретического спутника к разделу статьи про выбор того, что измерять, и почему большинство готовых метрик недооценивают реальные регрессии.
Эксперт
 55 мин
55 минВидео
How to Systematically Setup LLM Evals (Metrics, Unit Tests, LLM-as-a-Judge)
Dave Ebbelaar. Действующий AI-инженер проходится по своей реальной лестнице evals — unit-тесты в стиле assert, метрики без эталонов, согласование LLM-as-judge с людьми и цикл «анализируй–измеряй–улучшай». Структура — самое близкое совпадение на видео к тезису статьи, что evals — это система ловли регрессий, а не лидерборд.
Эксперт
 3 мин
3 минВидео
Evaluate prompts in the Anthropic Console
Anthropic. Трёхминутный разбор Anthropic о том, как запустить реальный eval внутри Workbench — автогенерация реалистичных тест-кейсов, оценка вывода, правка промпта и повторный прогон того же набора рядом для сравнения. Просмотры ниже обычной планки, но для «как мне реально это сделать без кода» это самое чистое официальное демо и аккуратно встраивается под более стратегический разговор Хусейн/Шанкар.
Уверенный
 107 мин
107 минВидео
Why AI evals are the hottest new skill for product builders | Hamel Husain & Shreya Shankar
Lenny's Podcast. Хамел Хусейн и Шрея Шанкар проходят весь воркфлоу evals на реальном ИИ-ассистенте по управлению недвижимостью — смотрят трассировки, открытое и осевое кодирование ошибок, решают, когда остановиться, строят LLM-as-judge и валидируют его против человеческого суждения. Это редкий длинный разговор, действительно нацеленный на продактов и тимлидов, а не на ML-инженеров, и он покрывает тот же ритм «30 минут в неделю после настройки», который рекомендует статья.
Уверенный